
Enseignant : M. PANSIOT
IUP 2ème année
2002 - 2003
1.1.1 Jeton sur
anneau (non adressé)
1.1.2 Jeton sur
bus (adressé) ou Token Bus
2) Normalisation des LAN : La norme
IEEE 802
2) Les ponts à routage par la source
III – Le routage
et les routeurs
1) Pourquoi une interconnexion au niveau
réseau ?
2.1 Les
principaux choix du protocole IP
3) Les protocoles annexes : ARP, ICMP
6) Le protocole de routage : OSPF
6.3 Découverte
des voisins et adjacence
6.4 Diffusion des
états et des liens
6.5 Calcul de la
table de routage
I - Les réseaux locaux
Qu'est ce qu'un réseau local (ou LAN : Local
Area Network) ?
Géographie limitée, de quelques mètres à quelques
kilomètres, d'où
Moins de contraintes
techniques è
haut débit
Moins de contraintes
réglementaires (domaine privé) è choix des technologies
Réseau d'égal à égal : toute machine peut discuter avec
toute machine
LAN = partage d'une infrastructure haut débit (câblage, éléments actifs)
1) Les méthodes
d’accès
Comment contrôler l'accès au réseau ? Comment
partager les ressources du réseau ?
Certaines méthodes inspirées des techniques classiques de multiplexage.
Méthodes statiques : partage en fréquence, ou temporel
Mal adaptées aux débits très irréguliers des applications
informatiques
Méthodes dynamiques : on distingue les méthodes a priori ou préventives,
qui évitent les conflits d'accès (méthodes à jeton par exemple), et les
méthodes a posteriori, où des conflits d'accès peuvent survenir
(collision) et doivent être résolus à posteriori.
Méthodes
préventives centralisées : système de polling (maître-esclave)
Une entité (maître) distribue (par exemple à tour de rôle)
le droit d'émettre aux entités esclave
Mal adaptées à un système d'égal à égal décentralisé,
problèmes de fiabilité.
Méthodes
préventives distribuées : méthodes à jeton
1.1.1 Jeton
sur anneau (non adressé)
Dans un réseau en anneau, les machines sont reliées
suivant un cycle (unidirectionnel ou bidirectionnel). L'interface réseau de
chaque machine peut être :
- en état répétition : dans ce cas les données reçues sont
retransmises en sortie après un délai de quelques bits.
- en état émission : la machine envoie en sortie une trame
locale, les données reçues en entrée ne sont pas réémises.
Le jeton est une trame particulière qui donne le droit d'émission (il y a au
plus un jeton en circulation). La machine qui désire émettre attend le passage
du jeton, le capture, émet une ou plusieurs trames, puis émet un jeton.
L'unicité du jeton garantit l'absence de conflits d'accès. Le jeton n'a pas
besoin d'être adressé explicitement : il est envoyé au suivant.
La très grande simplicité du principe de base ne doit pas cacher un certain
nombre de difficultés :
- que faire en cas de perte du jeton (suite à une erreur de
transmission ou une panne) ?
- la coupure d'un lien entraîne l'arrêt du réseau (dans un
anneau simple)
- qui supprime les trames circulant dans le réseau ?
- quand l'émetteur doit-il réémettre le jeton :
- au retour complet de ses trames , ce qui permet de gérer
en même temps un acquittement,
- au retour du début de sa trame,
- dès la fin d'émission des trames, ce qui optimise
l'utilisation du support, mais pose le problème de supprimer les trames en
circulation.
Les choix faits influent sur le taux d'utilisation du réseau (en fonction
du débit et de la taille de l'anneau).
Des variantes de cette méthode sont utilisées dans les réseaux IEEE 802.5 et
FDDI.
Un point important dans ces méthodes, c'est que le temps de rotation du jeton
(TRJ) peut-être majoré. Cela permet d'une part de garantir un délai d'attente
maximum pour un émetteur, et d'autre part cela permet d'assurer la
fiabilisation du jeton : si aucun jeton ne passe pendant une période TRJ, c'est
qu'il est perdu. Garantir le TRJ implique qu'une station ne peut émettre qu'une
quantité limitée à chaque capture de jeton.
La surveillance du jeton peut être faite
- par une station particulière (le moniteur), auquel cas il faut pévoir
l'élection d'un nouveau moniteur en cas de panne
- par toute les sations, auquel cas il faut désigner celle qui ré-émettra le
jeton
Exercice
à faire : calcul de la capacité d'un anneau (nombre de bits en circulation
simultanément). Nombre de trames ? La taille du jeton est-elle inférieure à la
capacité ?
1.1.2 Jeton
sur bus (adressé) ou Token Bus
Topologie sous-jacente: réseau à diffusion
(bus).
Les machines sont organisées en anneau logique, chaque machine connaît
son successeur dans l'anneau logique
Le jeton est adressé au successeur dans l'anneau.
Problèmes : insertion et retraits de machine
Insertion: la nouvelle machine ne peut envoyer spontanément de
trame car elle ne reçoit pas le jeton
Principe : à intervalle régulier, le possesseur du jeton
Demande s'il y a de nouveaux adhérents
Les nouveaux répondent
Ils sont insérés dans l'anneau logique
Problème : les réponses simultanées de plusieurs nouveaux
Mécanisme basé sur des délais (Comparable
aux méthodes aléatoires )
Retrait
(ou panne)
Mécanismes similaires à l'anneau à jeton :
Détection de la perte du jeton (par son dernier émetteur)
Reconstitution de l'anneau logique
Régénération du jeton
Ne convient pas pour des réseaux avec un fort taux d'adhésion retrait
(style bureautique)
Mieux adapté à des réseaux plus statiques et contrôlés (réseau
industriel)
Principe des réseaux IEEE 802.4 (MAP) utilisés par certains grands
industriels (automobile)
Méthodes
d'accès Aléatoires (sur réseau à diffusion)
1.1.3 Méthode
ALOHA
Environnement : stations reliées par radio,
utilisant la même fréquence
Algorithme : Si trame à émettre, émettre la trame
Possibilité
de collision (signaux de 2 émetteurs qui se superposent)
Les 2 (ou plus) trames sont alors fausses.
ALOHA ne traite pas les collisions : reprise sur erreur confiée à
une couche supérieure fiable comme HDLC, d'où des temps de reprise
assez élevés.
Avantage : délai avant émission réduit au minimum, protocole très simple
Inconvénients : délai de reprise sur collision élevé, le taux de collision
augmente avec le trafic.
Analyse probabiliste faite (avec des hypothèses pas toujours réalistes) :
Avec un nombre arbitrairement grand d'émetteurs indépendants, le débit utile
(trames émises sans collision) plafonne à 1/(2 e) (= 18%) puis tend vers 0
quand le débit offert augmente
Si l'émission d'une trame dure t, une trame émise au temps T0 peut
entrer en collision avec une trame émise entre les instants T0-t et
T0+t donc la période de vulnérabilité dure 2t.
Une amélioration consiste à discrètiser le temps : un TOP est envoyé à
intervalle t, et l'algorithme devient :
Si trame à émettre, alors attendre le prochain TOP et émettre.
La période de vulnérabilité ne dure plus que t.
Avec les mêmes hypothèses probabilistes, on peut montrer que le débit utile
plafonne à 1/e (=37%).
1.1.4 Méthode
CSMA
è CSMA
= Carrier Sense Multiple Access = Accès multiple et détection du signal
Suppose qu'un émetteur peut détecter l'occupation
du canal avant d'émettre.
Algorithme
Si trame à émettre alors
Si canal libre alors émettre la trame
Sinon attendre
On
distingue deux stratégies d'attente :
CSMA persistant : on scrute le canal jusqu'à sa libération puis on émet
Avantage : émission dès que possible
Inconvénient : deux (ou plus) candidats émetteurs qui attendent la fin de
la trame en cours vont certainement entrer en collision
CSMA non persistant : on attend un temps aléatoire, puis on réessaye
Avantage : limite le nombre de collision si les temps aléatoires sont
bien choisis
Inconvénient : On n'émet pas dès que possible, même à faible trafic. A
fort trafic, on n'est pas sûr de trouver le canal libre : pas de borne sur le
temps avant tentative d'émission.
Remarque
:
Avec CSMA il y a toujours des collisions, dues à des émissions simultanées ou quasi-simultanées,
au temps de propagation dans le réseau près. Contrairement à Aloha simple, les
collisions ont lieu en début de trame, car les autres émetteurs sont tous au
courant de l'émission après le temps de propagation dans le réseau. La période
de vulnérabilité dépend du temps de propagation.
Inconvénient CSMA : en cas de collision en début de trame, on continue à
émettre pour rien, d'où :
Méthode CSMA/CD (CD : Collision Detect = Détection de Collision)
Dans cette méthode les émetteurs peuvent détecter que la trame en cours
d'émission a subi une collision, en comparant le signal émis au signal présent
sur le canal.
L'Algorithme
devient alors :
Si trame à émettre alors
Si canal libre alors
Commencer à émettre
Si collision détectée alors arrêter d'émettre
Sinon attendre (suivant CSMA persistant ou non)
Le
dernier point à améliorer est la stratégie de retransmission en cas de
collision. On ne peut laisser la retransmission à la couche liaison car cela
prend trop de temps, donc il faut que le protocole d'accès assure la
retransmission. Cette retransmission ne peut pas être faite au bout d'un temps
fixe, car la collision se reproduirait systématiquement. Deux possibilités :
les délais avant retransmission dépendent des stations (système de priorité),
ou bien ce qui correspond mieux aux LAN, les délais sont aléatoires.
Méthode du Binary Exponential Backoff :
Le temps d'attente d'une station en cas de collision est de la forme
i * T, où T est l'unité de temps (tranche, de l'ordre du temps aller-retour
maximal dans le réseau), et i est un nombre entier tiré aléatoirement
dans l'intervalle [0, 2**k[ . k représente le numéro de la tentative de
retransmission de la trame.
A la première collision, i est donc tiré dans [0,2[, à la deuxième dans [0,4[,
etc ... La probabilité que deux stations entrent répétitivement en collision
décroît donc comme 2 ** (-n).
Les réseaux locaux très répandus comme IEEE 802.3/Ethernet utilisent la méthode
CSMA/CD avec Binary Exponential Backoff.
EXERCICES
à faire sur cet algorithme
2) Normalisation des
LAN : La norme IEEE 802
Issue du Comité 802 de l'IEEE (Institute of
Electrical and Electronic Engineers)
Structure de la norme :
Couches Physique et MAC (Medium Access Control) : 802.3 (méthode CSMA/CD persistant)
802.4 (Bus à jeton), 802.5 (anneau à jeton),... 802.11 (LAN sans fil),...
Couche LLC (802.2)
Architecture générale et pontage : 802.1
La
couche liaison de l'ISO est donc découpée en MAC + LLC
Lien entre normes ISO et IEEE :
La plupart des normes IEEE 802 sont reprises par l'ISO :
IEEE 802.3 => ISO 8802-3 (idem pour 2, 4,5 ).
2.1 La
norme 802.3
Issue de ALOHA, puis des protocoles CSMA/CD. A
l'origine une spécification de Xerox/Intel/Digital : Ethernet, normalisée par
l'IEEE avec quelques modifications.
v
Partie physique :
Initialement câble coaxial épais : segment de 500m
maximum, connexion sur le câble par prises vampires (perçage du câble).
Distance entre deux prises multiple de 2,5 m. Ce câblage est baptisé 10Base5
(10 Mb/s, transmission en bande de base sur 500 m).
Un autre câble coaxial plus fin existe, avec des segments limités à 200m : 10Base2.
Pas de possibilité de prise vampire. Connecteurs de type BNC.
La connexion à la machine peut se faire par une électronique externe, le transceiver
(ou MAU = Medium Access Unit). Ce boîtier a une interface spécifique au
câble (vampire, BNC, RJ45, optique) et une interface normalisée AUI (connecteur
15 broches). Une interface semblable symétrique existe sur certaines cartes
réseau. La connexion entre carte et transceiver peut se faire directement ou
plus généralement par un câble spécifique, appelé câble de descente (ou
drop). La longueur de ce câble est limitée par la norme à 50m.
Les câblages de type bus coaxial posent des problèmes, en particulier de
fiabilité et de maintenance : un problème avec un connecteur peut stopper tout
le réseau et être très difficile à localiser. Grâce aux progrès des
technologies de transmission, un câblage 10 Mb/s sur paires torsadées
(semblable à un câblage téléphonique de bonne qualité) a été défini. La norme
802.3 10BaseT (T pour Twisted Pairs) définit un segment point à point de
100m maximum, utilisant 2 paires torsadées (1 émission, 1 réception). Le
connecteur standardisé est le RJ45 (qui comporte 8 contacts dont 4 sont
utilisés par 10baseT).
Note : il est donc possible de créer un réseau 10baseT de 2 machines en
les reliant directement par un câble paires torsadées (croisé), si les machines
ont une interface 10BaseT. Il existe aussi une spécification pour Fibre optique
(10BaseF), où la distance est limitée à 2km en point à point sur
Fibre Optique Multimode.
Les réseaux composés d'un seul segment (coaxial ou paire torsadée) sont très
limités tant en distance qu'en nombre de machines (2 pour 10baseT ou 10BaseF).
La norme a donc prévu des répéteurs qui permettent d'interconnecter des
segments. Le rôle essentiel d'un répéteur est d'amplifier le signal reçu sur un
port d'entrée et de le réémettre sur tous les autres ports. Les répéteurs
initiaux étaient souvent limités à deux segments. Avec l'arrivée de LAN de plus
en plus étendus, et de réseaux 10BaseT, le nombre de ports (segments) par
répéteur a augmenté. On parle alors parfois de hub ou de concentrateur
(4,8,16,... ports). Les machines sont alors connectées en étoile autour d'un ou
plusieurs hub. L'interconnexion des répéteurs ne doit pas comporter de boucles
sous peine d'arrêt du réseau.
Note : un répéteur peut permettre de raccorder des segments utilisant des
câblages différents (10Base5, 10Base2, 10BaseT, 10BaseF), pourvu que la vitesse
soit la même.
Il a existé des spécifications de réseau 802.3 à 1 Mb/s (1base5) et il existe
maintenant des variantes à 100 Mb/s (100BaseT sur paires torsadées )
ou 1 Gb/s (1000BaseT sur paires torsadées).
Remarque : de plus en plus d'interfaces ethernet peuvent s'adapter
automatiquement à la vitesse du réseau (10/100/1000 Mb/spar exemple), et
peuvent passer en mode full-duplex. Ceci n'est possible que sur une liaison
point à point (machine- commutateur par exemple. Dans ce cas, il n'y a plus de
collision.
v
La trame 802.3
Les réseaux de type 802.3 fonctionnent par émission
de trames de taille limitée. Le format d'une trame est le suivant :
Préambule : 7 octets de valeur 10101010
Un délimiteur de trame d'un octet 10101011
Une adresse destination (codée sur 2 ou 6 octets)
Une adresse source (idem)
La longueur de la trame (depuis l'adresse destination)
Les données du niveau supérieur
Un code détecteur d'erreur sur 4 octets
Le préambule sert à synchroniser les
récepteurs sur l'émetteur grâce à un signal périodique. Les premiers bits du
préambule peuvent être perdus sans inconvénient. Le délimiteur sert à
déterminer le début effectif de la trame.
Les adresses sont généralement codées sur 6 octets (la variante 2 octets étant
peu utilisée). Les deux premiers bits de l'adresse ont une signification
spéciale. Le premier bit (le bit de poids faible du premier octet) indique s'il
s'agit d'une adresse individuelle (d'une carte réseau d'une machine) (bit à 0),
ou d'une adresse de groupe (bit à 1). Les adresses de groupe sont interdites
comme adresse source. L'adresse comportant seulement des 1 est une adresse de
groupe particulière : le broadcast (toutes les machines du LAN). Les
autres adresses de groupe sont appelées adresses multicast. Le deuxième
bit indique si les adresses sont attribuées universellement (bit à 0) ou
localement (bit à 1). Généralement la première solution est retenue : chaque
carte réseau est dotée d'une adresse universelle par défaut, stockée en mémoire
non volatile. Pour assurer l'unicité globale de l'adresse, elle est codée sous
la forme de 3 octets pour le numéro du fabricant et 3 octets pour un numéro de
série (attribué par le fabricant à chacune de ses cartes).
Exercice domino : décoder les adresses de quelques
trames : multicast, broadcast, fabricants,...
Le champ longueur compte les octets depuis
l'adresse destination jusqu'au code détecteur inclus.
La partie donnée contient les données du protocole de niveau supérieur
(normalement LLC 802.2 au-dessus de 802.3). La norme limite la taille des
données entre 46 et 1500 octets. Si les données utiles font moins de 46 octets,
elles doivent être suivies d'octets de bourrage (padding).
Le code détecteur utilisé est un code polynomial utilisant un polynôme de 32
bits (Frame Check sequence : FCS):
g(x)=x32+x26+x23+x22+x16+x12+x11+x10+x8+x7+x5+x4+x2+x1+1.
Différence entre la trame 802.3 et ethernet
: le champ Longueur (802.3) devient Type (Ethernet). Le type est un
numéro identifiant le protocole utilisé au-dessus d'ethernet, généralement un
protocole de niveau réseau comme IP (type 0x800), IPX (Novell) ou
AppleTalk. Les deux types de trame peuvent coexister sur le même réseau,
et aussi sur la même machine, les valeurs possibles pour une longueur 802.3 et
un type ethernet étant disjointes (Peut être vérifié en exercice). Le
champ type est inutile dans la trame 802.3 car le protocole de niveau supérieur
est à priori toujours 802.2 (niveau LLC). Pour utiliser des protocoles de
niveau 3 différents au-dessus de 802.2, on utilise une couche intermédiaire
(SNAP) qui contient l'équivalent du champ type. On a donc par exemple :
<entête ethernet> <paquet IP>
ou
<entête 802.3> <entête 802.2> <entête SNAP>
<paquet IP>
L'entête 802.2 contient comme SAP (Service Access Point) le code
0xAA (qui indique l'utilisation de SNAP) et un champ commande de type UI
(trame non numérotée, code 0x03). Cet entête 802.2 est donc fixe et égal à 0xAA
0xAA 0x03.
L'entête SNAP comporte 2 champs, un champ de 3 octets spécifiant l'autorité
(entreprise par exemple) qui a défini le protocole puis un champ de deux octets
contenant le numéro de protocole. Pour IP ces deux champs valent respectivement
0 et 0x800.
Pour une description des codes utilisés dans le
champs type et les codes des constructeurs utilisés dans les adresses, voir par
exemple: cavebear.com
Acceptation des trames : ethernet étant un réseau à
diffusion, toute machine reçoit toutes les trames émises par tous les
émetteurs. La carte réseau opère le filtrage suivant en réception :
1) Vérifier que la trame est correcte (longueur
valide, pas d'erreur détectée grâce au FCS). Une trame incorrecte est ignorée,
sans signalement à l'émetteur. Une trame trop courte est en général un fragment
dû à une collision. La présence de fragments sur un réseau chargé est donc
normale.
2) Pour les trames correctes, l'adresse destination est comparée à une liste
d'adresses acceptées. Par défaut cette liste contient l'adresse MAC (ethernet)
de l'interface, et l'adresse broadcast. Par configuration on peut modifier
cette liste, en particulier y ajouter des adresses multicast. Les trames
envoyées à une adresse non acceptée sont ignorées, les autres sont fournies au
système et donc aux protocoles de niveau supérieur. Cas particulier :
l'interface peut être mise en mode "promiscuous " (écoute).
Dans ce cas toutes les trames sont acceptées. Ceci est utile pour des outils de
gestion réseau. Cette possibilité pose un problème de sécurité évident.
v
Dimensionnement : Considération de temps et
longueur minimale des trames
Considérons deux stations A et B, séparées par un
temps de propagation p.
Au temps T0, A commence à émettre une trame. Au temps T0
+ p, le signal de A commence à arriver en B. Dans le cas le pire, B décide
d'émettre juste avant T0+p (T0 +p - e). A cet instant le
canal est libre, donc d'après CSMA, B commence à émettre. Au temps T0
+ p, B constate une collision (superposition des signaux de A et B), et arrête
d'émettre, après avoir respecté une période de brouillage. Le signal de B
arrive en A au temps T0+ 2p -e. D'après CSMA/CD, A ne détecte la
collision que s'il est encore en train d'émettre. Donc la durée d'émission
minimale (égale à L/d) doit être supérieure à 2p, où L est la longueur minimale
de la trame et d le débit binaire:
L/d > 2p
Le paramètre p dépend principalement de la
configuration du réseau. On a donc une contrainte qui lie taille du
réseau, débit et taille minimale des trames.
Le choix fait par 802.3 est de fixer L à 512 bits (64 octets),
indépendamment du débit. Pour un réseau à 10 Mb/s, on a 2p < 51,2 µs : le
temps aller-retour dans le réseau, et donc la taille sont limités. La valeur de
p dépend principalement du temps de traversée et du nombre d'équipements
électroniques (répéteurs, transceivers,...), et du temps de propagation dans
les câbles (donc de leur longueur, la vitesse de propagation étant voisine de
200000 km/s).
Le nombre de répéteurs situés en ligne (sur le chemin entre deux stations) est
limité à 4 par la norme 802.3.
Donner les valeurs des temps de traversée par équipement et calculer des
"bit budgets " (exemples dans la norme 802.3).
Remarque : si on décuple le débit (ethernet 100Mb/s), on doit donc diviser par
10 le temps de propagation, donc la taille du réseau. Cette approche est
difficilement applicable à des débits supérieurs, c'est pourquoi dans gigabit
ethernet (ethernet 1000Mb/s), les trames doivent être agrégées ou suivies de bourrage
pour augmenter le temps de transmission minimal sans augmenter la longueur
minimale des trames.
Nous avons déjà vu que les réseaux ethernet commutés avec liens full-duplex
n'ont pas de problème de collision, et donc pas les mêmes contraintes de taille
de réseau.
Limitations d'ethernet :
- en taille géographique (à cause du temps de propagation)
- en débit : toutes les machines partagent la même bande passante : un seul domaine
de collision
- la vitesse doit être la même sur tout le réseau (même si les segments peuvent
être de nature différente : coaxial, paire torsadée, fibre, sans-fil,... )
II - Les ponts
Objectifs :
- dépasser les limitations géographiques des LAN (plus grandes distances)
- plus de machines
- augmenter le débit disponible en filtrant
- autoriser la connexion de LAN ayant des débits ou des méthodes d'accès
différents
- permettre la redondance
- nécessiter le moins possible de configuration par l'administrateur.
Principe :
un pont est un équipement doté d'au moins deux
interfaces réseau, connectant des LANs. Les trames reçues par une interface
sont éventuellement retransmises sur une ou plusieurs autres interfaces. Un
pont se place donc au niveau 2 du modèle OSI. La plupart des ponts
fonctionnent sur le mode "Store and Forward ", c'est-à-dire que la
trame est lue et stockée complètement (store) avant d'être réémise. Il existe
aussi des ponts "Cut Through " où une trame est réémise dès que
possible (en général réception de l'adresse destination). Ce mode plus rapide
pose de nombreux problèmes.
Il est à noter qu'un pont peut être vu comme un simple ordinateur avec au moins
deux cartes réseaux, et qui écoute (mode "promiscuous ") toutes les
trames sur ses interfaces. Les commutateurs (switch) ethernet (ou
plus généralement commutateurs de trame, de LAN) sont des ponts avec un assez
grand nombre d'interfaces (par exemple 8, 16, 32, ...).
Ponts distants : Deux ponts
peuvent aussi être reliés par une liaison série longue distance : les trames
MAC sont alors encapsulées dans le protocole de liaison utilisé (par exemple
HDLC).
Cela permet d'étendre encore les LAN avec pont, au détriment des performances
si la liaison point à point est moins rapide que les Lans interconnectés.
Deux architectures sont proposées : les ponts
transparents (qui sont totalement invisibles par les machines et
qui utilisent le protocole de Spanning Tree), et les ponts par routage
source. Les premiers sont principalement utilisés par les LAN 802.3, 802.4
et FDDI, les seconds par IEEE 802.5.
1) Les ponts
transparents
Ils sont décrits dans la
norme IEEE 802.1D
1.1 La
table de propagation
Chaque pont possède une table (Forwarding
Database). Une entrée de la table contient au moins :
Adresse Mac, interface, age
Lorsqu'une trame à destination de l'adresse d est reçue par l'interface i, on
la traite de la façon suivante :
- si la trame est incorrecte elle est ignorée
- si l'adresse d est associée à l'interface i dans la table, la trame est
ignorée
- si l'adresse d est associée à une autre interface j, elle est retransmise
vers j
- si l'adresse d ne figure pas dans la table (ou bien si c'est une adresse
multicast ou broadcast), elle est réémise vers toutes les interfaces sauf i.
On voit que les adresses inconnues sont propagées vers tous les LAN, ce qui
n'est pas très efficace.
Construction de la table : Elle est automatique ("auto apprentissage
") :
A l'arrivée d'une trame de source s par l'interface i, on met à jour la table
en associant à s l'entrée (s, i, 0). Périodiquement l'age de chaque entrée est
incrémenté. Une adresse qui n'est plus active voit donc son age augmenter
jusqu'à un seuil où elle est éliminée de la table.
Note (pas fait en cours) : lors d'un changement de topologie, l'interface
correspondant à une adresse peut changer. Dans ce cas l'age maximum est diminué
pour remettre plus vite à jour la table.
Problème : les boucles.
Si l'interconnexion contient une boucle volontaire (redondance) ou non
(erreur de branchement), une trame peut circuler indéfiniment. Plus grave, s'il
y a deux cycles dans le réseau, la trame se duplique à chaque tour, donnant une
explosion exponentielle des trames et un effondrement du réseau.
Exercices possibles :
- comparer les temps de transmission d'une trame ethernet
suivant qu'elle traverse des ponts plutôt que des hubs
- regarder ce qui se passe avec les collisions
- éventuellement placement judicieux de ponts suivant le trafic entre clients
et serveurs.
- étudier les problèmes des ponts cut through
-
TP examiner la
table de propagation d'un pont (age, ....) .
Action:
forward: propager les trames
discard : ignorer ces trames
Age: P = permanent (indique une entrée configurée manuellement)
RX count et TX count : nombre de trames reçues et émises avec cette adresse)
|
Address |
Action |
Interface |
Age |
RX count |
TX count |
|
aa00.0400.d4d4 |
forward |
Ethernet8 |
1 |
2305 |
0 |
|
0100.8100.0101 |
discard |
- |
P |
0 |
0 |
|
0100.8100.0100 |
discard |
- |
P |
0 |
0 |
|
0080.c8f2.979f |
forward |
Fddi0 |
4 |
15 |
0 |
|
aa00.0400.dcd4 |
forward |
Ethernet8 |
0 |
40710 |
0 |
|
00a0.4b00.dfd6 |
forward |
Ethernet10 |
0 |
30 |
0 |
|
0080.c81e.4f44 |
forward |
Fddi0 |
1 |
21 |
0 |
|
0005.0222.5243 |
forward |
Ethernet7 |
1 |
2 |
0 |
|
0005.0261.7d6e |
forward |
Ethernet10 |
1 |
0 |
0 |
…
Changer la topologie ou la localisation d'une machine et
analyser les conséquences.
1.2 Spanning
Tree Protocol
Objectifs :
- permettre des ponts transparents (rien à faire sur les stations)
- autoriser une redondance physique (volontaire on non)
- éviter les trames qui bouclent
- s'adapter rapidement aux changements de configuration (volontaires ou non)
- boite noire (pas de configuration)
- reproductibilité (à configuration physique identique, la configuration
logique est la même quels que soient les événements antérieurs).
Principe :
Le
réseau est un graphe biparti (deux types de noeuds : les ponts et les LAN). Les
arêtes sont les connexions LAN-pont (port ou lien). A partir de ce graphe
connexe, il s'agit d'éliminer les boucles tout en maintenant la connexité, donc
de construire un arbre de recouvrement du graphe (spanning tree).
En pratique, l'arbre construit est un arbre des plus courts chemins depuis un
pont jouant un rôle particulier, la racine (root).
Chaque pont a un identificateur constitué d'une priorité et de son adresse Mac.
Donc même en l'absence de configuration (= priorité par défaut), tous les
identificateurs sont distincts. Le pont de plus petit identificateur est choisi
comme racine. La priorité permet à l'administrateur réseau de choisir quel pont
sera la racine.
L'algorithme repose sur la transmission d'un message HELLO (Configuration
Bridge Protocol Data Unit : BPDU) contenant en particulier les
paramètres suivants :
- identité de la racine
- distance de la racine au pont émetteur du BPDU
- identité du pont émetteur
- port d'émission du message.
Grandes lignes de l'algorithme :
Le pont désigné comme racine envoie périodiquement des messages HELLO sur tous
ses ports désignés (par exemple 2 secondes).
Chaque pont
- mémorise pendant un certain temps les messages HELLO reçus sur ses interfaces
- détermine son port vers la racine (c'est le port par lequel on connaît le
plus court chemin vers la racine, les ex-aequo sont départagés par les numéros
de port)
- détermine s'il est désigné pour certains LANs, ce qui signifie qu'il est sur
le plus court chemin de la racine vers ce LAN, de nouveau les ex-aequo sont
départagés par identité du pont, puis par numéro de port. Le port
correspondant est donc désigné. Les ports vers la racine ou désignés
font partie du spanning tree et transmettront des données dans les deux sens.
Les autres sont redondants et ne transmettront pas de trames (à l'exception des
BPDU).
- A réception d'une trame HELLO, un pont vérifie
- Si les infos sont les
mêmes que celles déjà connues, le message est propagé vers les ports désignés
(après mise à jour des champs)
- Si les infos sont différentes, et "meilleures " (racine d'identité
inférieure ou distance à la racine inférieure) il y a mise à jour locale et des
ports racine et désignés
- Si les infos sont "moins bonnes " (racine d'identité supérieure ou
distance à la racine supérieure), le message n'est pas utilisé
- Si un message HELLO mémorisé n'est pas validé par
un nouveau message, il est éliminé après un certain délai (par exemple 30s). Si
la suppression de ce message fait qu'il n'y a pas (plus) de chemin connu vers
la racine (ou au démarrage du pont), le pont devient candidat racine et
commence à envoyer lui-même des messages HELLO.
Comportement en terme de transmission de données : un port qui n'est pas racine
ni désigné est mis dans l'état bloquant. Les trames autres que BPDU ne
sont pas envoyées ni reçues sur ce port. Les passages de l'état bloquant à
non-bloquant et réciproquement sont soumis à des temporisations, pour éviter
les oscillations et les boucles temporaires.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|

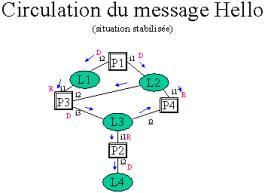



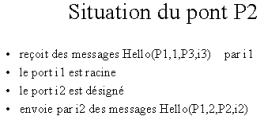
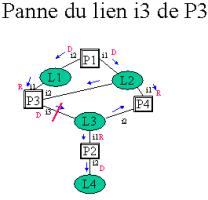




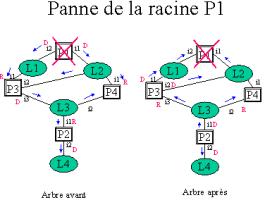




Inconvénient
des ponts transparents :
- le matériel redondant n'est pas mis à profit pour faire du partage de charge
: il est simplement mis en attente d'un changement de configuration
- le chemin emprunté par les trames (l'unique chemin dans l'arbre) n'est pas
forcément le plus court chemin dans la topologie physique sous-jacente.
Exercices
: faire dérouler le STP sur divers graphes et illustrer ce qui se passe en cas
de changement de topologie (rupture d'un cycle, partitionnement, panne de la
racine, arrivée d'un nouveau pont).
TP
: maquette avec des ponts. Analyser la configuration
du spanning tree . Analyser les trames BPDU ; refaire les exercices en réel
et observer.
NOTE : avec tcpdump
tcpdump -x ether[12:2] \<
0x600 and ether[14:2] = 0x4242
19:36:25.410845 802.1d Conf root=8000-0:20:da:82:52:60 cost=0
bridge=80000:20:da:82:52:60 80-1
4242 0300 0000 0000 8000 0020 da82 5260
0000 0000 8000 0020 da82 5260 8001 0000
1400 0200 0f00
19:36:27.411199 802.1d Conf root=8000-0:20:da:82:52:60 cost=0
bridge=80000:20:da:82:52:60 80-1
4242 0300 0000 0000 8000 0020 da82 5260
0000 0000 8000 0020 da82 5260 8001 0000
1400 0200 0f00
Trafic SNAP :
root@crc[~]:tcpdump -x ether[12:2] \< 0x600 and
ether[14:2] = 0xaaaa and ether[16] = 0x03
tcpdump: listening on hme0
19:44:50.517422 3.231.191.rtmp > 0.0.rtmp: at-rtmp 22
aaaa 0308 0007 809b 0023 0000 0000 03e7
ffbf 0101 0103 e708 bf03 e780 03e7 8203
e780 03e7 8213 8880 1388 82
19:44:51.882974 0:0:81:39:e:f1 > 1:0:81:0:1:0 sap aa ui/C len=8
fa39 0ef1 0902 0201
aaaa 0300 0081 01a2 824f c8fa 390e f109
0202 01
19:44:51.887647 0:0:81:39:e:f1 > 1:0:81:0:1:1 sap aa ui/C len=8
fa39 0ef1 0902 0201
aaaa 0300 0081 01a1 824f c8fa 390e f109
0202 01
Les
états d'un port pour la propagation des données :
1) Inactif / Disabled (à l'initialisation ou suite à une panne)
2) Ecoute / Listening (à l'écoute des messages BPDU)
3) Apprentissage / Learning (la table d'adresse est mise à jour à partir
des adresses sources des trames arrivant par le port)
4) Propagation / Forwarding (l'apprentissage continue, et les trames de données
sont propagées)
5) Bloquant / Blocking (les trames de données sont
filtrées, les BPDU analysés)
Quand un port quitte l'arbre, il passe dans l'état
bloquant. Inversement, un port qui est ajouté à l'arbre passe de bloquant à
Ecoute, puis après un délai à apprentissage, puis finalement propagation.
Changement de topologie : quand l'arbre change, la table de propagation
peut devenir fausse (une adresse MAC ne doit plus être vue par la même
interface). La durée de vie normale d'une entrée dans la table est longue (pe
30 minutes). Pour accélérer la mise à jour le mécanisme suivant est ajouté :
Tout pont qui détecte un changement de topologie ou qui reçoit un
"changement topologie BPDU "envoie un
"changement topologie BPDU " sur son port racine (sauf pont
racine), et ceci pendant un certain temps.
La racine qui reçoit un message " changement topologie BPDU "
positionne un bit spécial dans les messages HELLO. Tous les ponts sont
donc avertis du changement.
Tout pont qui est averti d'un changement diminue le délai de garde des adresses
dans sa table,
Et ceci pendant un certain temps.
Commutation par port : discussion sur les problèmes potentiels de performance
dans un réseau avec commutateurs : risque de surcharge de certains ports ce qui
entraîne :
- délais de traversés plus longs
- pertes de paquets.
2) Les ponts à routage
par la source
Autre solution préconisée par l'IEEE et
principalement adoptée par les réseaux token ring 802.5.
Principe : les trames sont marquées par un bit qui indique si le destinataire
est sur le même LAN ou non. Les trames destinées au même LAN ne sont pas
analysées par les ponts.
Les autres trames contiennent la route explicite pour joindre le destinataire,
sous la forme Lan 1, Pont1, Lan2, Pont2, Lan3,.... Chaque pont examine s'il
figure dans la route.
- Si non, il ignore la trame
- Si oui, il la propage vers le prochain Lan dans la route.
Dans ce système, les ponts n'ont pas besoin
d'information sur la localisation des machines, par contre, les stations
doivent maintenir une table qui pour chaque correspondant (adresse mac) donne
la route à utiliser. Ce mode n'est donc pas transparent pour les stations.
L'adressage des ponts et LAN doit aussi être configuré par l'administrateur.
Construction de la table d'une station : si une destination est inconnue, une
trame de recherche est envoyée par la station , et propagée par tous les ponts.
Au passage, chaque pont ajoute la route parcourue. Lorsque la trame arrive au
destinataire, elle contient donc la route depuis l'émetteur. Elle est retournée
à celui-ci qui complète sa table.
Avantage : avec cette méthode on peut utiliser la route la plus courte du
graphe, et il y a une forme de partage de charge entre ponts redondants.
Inconvénient : outre la non transparence, la mise à jour de la table des routes
pose problème en cas de changement de topologie. Si une route utilisée entre A
et B n'est plus disponible, la communication entre A et B est rompue tant que
la table n'est pas mise à jour, même si une autre route existe. La mise à jour
pourrait être déclenchée en l'absence d'accusé de réception (mais il n'y en a
pas au niveau Mac ethernet par exemple).
III – Le routage et les routeurs
1) Pourquoi une
interconnexion au niveau réseau ?
Un ensemble de réseaux locaux, reliés par des ponts
locaux ou distants forme un domaine de diffusion (ou de broadcast). Un
tel domaine, même s'il peut être géographiquement étendu (ponts distants) et
comporter plusieurs milliers de machines, présente un certain nombre de
limitations qui empêchent un déploiement à très grande échelle :
- dans un domaine de broadcast, les trames envoyées en broadcast, en multicast,
ou même de destinataire inconnu sont propagées dans tout le domaine, d'où un
bruit de fond qui croît avec le nombre de machines
- il n'y a pas de partage de charge, tout le traffic utilise les liens de
l'arbre de recouvrement
- l'arbre n'est pas stable à grande échelle: la panne de la racine à un bout du
réseau peut modifier l'arbre à l'autre bout
- les ponts transparents doivent maintenir une table avec une entrée par
machine active (pas de possibilité d'agréger les adresses car l'adressage MAC
est indépendant de la localisation)
- il est très difficile de contrôler les communications (filtrage, routes
différentes) en fonction des utilisateurs.
- l'usage des ponts est délicat voir impossible pour connecter des réseaux de
technologies différentes
Pour toutes ces raisons, un domaine de diffusion est limité
- à une seule entité (intra-domaine)
- à une aire géographique limitée et à des LAN compatibles
- à un nombre de machines limité (jusqu'à quelques milliers par exemple).
En dehors de ces cas, l'interconnexion se fait au niveau réseau (couche 3 du
modèle OSI), et met en oeuvre un protocole réseau (comme IP), des
protocoles de routage et des protocoles annexes liés à l'adressage et à
l'administration.
2) Le protocole IP
2.1 Les
principaux choix du protocole IP
Le protocole IP (Internetwork Protocol, défini dans
le RFC 791) est le standard actuel d'Internet pour la couche réseau. Ses
principales caractéristiques sont les suivantes :
- protocole sans connexion (datagramme) : les paquets IP sont envoyés sans
connexion préalable, contrairement à X25 ou ATM. Les différents paquets d'une
communication sont a priori acheminés indépendemment.
- en conséquence, il n'y a pas de reprise sur erreur : des paquets peuvent se
perdre, ou être déséquencés. Les deux sens de transmission peuvent utiliser des
chemins différents. La fiabilité, si nécessaire, est assurée dans les couches
supérieures. On parle de service au mieux (ou Best Effort).
- IP peut fonctionner au dessus d'à peu près n'importe quelle couche liaison
(ou assimilée) : LAN, liaisons téléphoniques avec PPP, X25, ATM, liaisons
satellites,....
- des protocoles de transport différents peuvent être utilisés au dessus d'IP
(même si deux protocoles, TCP et UDP sont de loin les plus répandus).
- IP permet d'interconnecter des réseaux hétérogènes, en particulier grâce à la
fragmentation.
2.2 Le paquet IP
L'entête IP comporte une partie fixe de 20 octets
plus des options éventuelles (d'au plus 40 octets au total).
Les données circulent sur Internet sous forme de datagrammes (on parle aussi de paquets).
Les datagrammes sont des données encapsulées,
c'est-à-dire des données auxquelles on a ajouté des en-têtes correspondant à
des informations sur leur transport (telles que l'adresse IP de destination,
...).
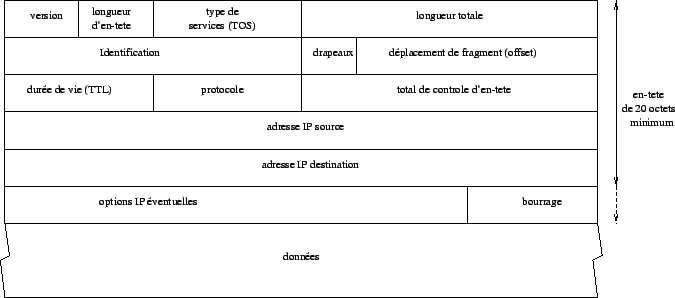
Voici la signification des différents champs :
v
Version : (codée sur 4
bits) il s'agit de la version du protocole IP que l'on utilise
(actuellement on utilise la version 4 IPv4) afin de vérifier la validité
du datagramme. Ainsi, tout logiciel IP doit d'abord vérifier que le numéro de
version du datagramme qu'il reçoit est en accord avec lui-même si ce n'est pas
le cas le datagramme est tout simplement rejeté
v
Longueur d'en-tête : (codée
sur 4 bits) elle représente la longueur, en nombre de mots de 32 bits, de
l'en-tête du datagramme. Ce champ est nécessaire car une entête peut avoir une taille
supérieure à 20 octets (taille de l'en-tête classique) à cause des options que
l'on peut y ajouter.
v
Type de services (TOS,
codé sur 8 bits), il indique la manière dont doit être géré le datagramme et se
décompose en six sous-champs comme suit.
|
Bit |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
Utilisation |
priorité |
D |
T |
R |
C |
- |
||
Le champ priorité varie de 0 (priorité
normale, valeur par défaut) à 7 (priorité maximale) et permet
d'indiquer l'importance de chaque datagramme. Même si ce champ n'est pas pris
en compte par tous les routeurs, il permettrait d'envisager des méthodes de
contrôle de congestion du réseau qui ne soient pas affectées par le problème
qu'elles cherchent à résoudre.
Les 4 bits D, T, R et C permettent de
spécifier ce que l'on veut privilégier pour la transmission de ce datagramme
(RFC 1455) :
§
D est mis à 1 pour essayer de minimiser le délai
d'acheminement (par exemple choisir un câble sous-marin plutôt qu'une
liaison satellite)
§
T est mis à 1 pour maximiser le débit de
transmission
§
R est mis à 1 pour assurer une plus grande
fiabilité
§
C est mis à 1 pour minimiser les coûts de
transmission.
Si les quatre bits sont à 1, alors c'est la sécurité de la transmission qui doit être maximisée. Les valeurs recommandées pour ces 4 bits sont :
|
|
Delay |
Throughput |
Reliability |
Cost |
|
|
minimise le délai |
maximise le débit |
maximise la fiabilité |
minimise le coût |
|
TELNET |
1 |
0 |
0 |
0 |
|
FTP |
|
|
|
|
|
Contrôle |
1 |
0 |
0 |
0 |
|
Transfert |
0 |
1 |
0 |
0 |
|
SMTP |
|
|
|
|
|
Commandes |
1 |
0 |
0 |
0 |
|
Données |
0 |
1 |
0 |
0 |
|
NNTP |
0 |
0 |
0 |
1 |
|
SNMP |
0 |
0 |
1 |
0 |
Remarque : Ces 4 bits
servent à améliorer la qualité du routage et ne sont pas des exigences
incontournables. Simplement, si un routeur connaît plusieurs voies de sortie
pour une même destination il pourra choisir celle qui correspond le mieux à la
demande.
v
Longueur totale :
(codée sur 16 bits) elle indique la taille totale du datagramme en
octets. La taille de ce champ étant de 2 octets, la taille totale du datagramme
ne peut dépasser 65536 octets. Utilisé conjointement avec la taille de
l'en-tête, ce champ permet de déterminer où sont situées les données
v
Les champs identification, drapeaux
et déplacement de fragment interviennent dans le processus de
fragmentation des datagrammes IP et seront décrit ci-après.
v Durée
de vie (TTL, codé su 8 bits) indique le nombre maximal
de routeurs que peut traverser le datagramme. Elle est initialisée à N
(souvent 32 ou 64) par la station émettrice et décrémenté de 1 par chaque
routeur qui le reçoit et le réexpédie. Lorsqu'un routeur reçoit un datagramme
dont la durée de vie est nulle, il le détruit et envoie à l'expéditeur un
message ICMP. Ainsi, il est impossible qu'un datagramme «boucle» indéfiniment.
Ce champ sert également dans la réalisation du programme traceroute.
Protocole (codé
su 8 bits) il permet de savoir de quel protocole de
plus haut niveau est issu le datagramme.
Exemple de valeurs :
Ø ICMP : 1
Ø IGMP : 2
Ø TCP : 6
Ø
UDP :17
Ainsi, la station qui reçoit un datagramme IP pourra diriger les données qu'il contient vers le protocole adéquat.
Total de contrôle d'en-tête (header checksum, codé sur 16 bits) il est calculé à partir de l'en-tête du datagramme pour en assurer l'intégrité. L'intégrité des données transportées est elle assurée directement par les protocoles ICMP, IGMP, TCP et UDP qui les émettent. Pour calculer cette somme de contrôle, on commence par la mettre à zéro. Puis, en considérant la totalité de l'en-tête comme une suite d'entiers de 16 bits, on fait la somme de ces entiers en complément à 1. On complémente à 1 cette somme et cela donne le total de contrôle que l'on insère dans le champ prévu. A la réception du datagramme, il suffit d'additionner tous les nombres de l'en-tête et si l'on obtient un nombre avec tous ses bits à 1, c'est que la transmission s'est passée sans problème.
Exemple : Soit le datagramme IP
dont l'en-tête est la suivante :
4500 05dc e733 222b ff11 checksum c02c 4d60 c02c 4d01
|
Mot
de 16 bits |
Complément
à 1 |
|
4500 |
baff |
|
05dc |
fa23 |
|
e733 |
18cc |
|
222b |
ddd4 |
|
ff11 |
00ee |
|
c02c |
3fd3 |
|
4d60 |
b29f |
|
c02c |
3fd3 |
|
4d01 |
b2fe |
|
Somme de
complément à 1 (S) |
8f18 |
|
Complément à 1
de S |
70e7 |
è
Le datagramme est donc expédié avec la valeur de checksum 70e7.
v
Adresse IP Source :
(codée sur 16 bits) elle représente l'adresse IP de la machine
émettrice, il permet au destinataire de répondre.
v
Adresse IP destination :
(codée sur 16 bits) c’est l’adresse IP du destinataire du message
v
Le champ options est une liste de longueur
variable, mais toujours complétée par des bits de bourrage pour
atteindre une taille multiple de 32 bits pour être en conformité avec la convention
qui définit le champ longueur de l'en-tête.
Ces options sont très peu utilisées car peu de machines sont aptes à les gérer. Parmi elles, on trouve des options de sécurité et de gestion (domaine militaire), d'enregistrement de la route, d'estampille horaire, routage strict, etc...
Exemple : LSRR (Loose Source Routing and Recording) paquet pour
Destination passant obligatoirement par R1 puis R2
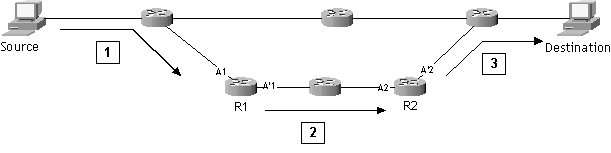
|
1 |
|
… |
S |
A1 |
… |
0 |
A2 |
D |
|
|
|
standard |
option |
|||||
|
|
|
|
|
|
|
|
|
|
|
2 |
|
… |
S |
A2 |
… |
1 |
A’1 |
D |
|
|
|
standard |
option |
|||||
|
|
|
|
|
|
|
|
|
|
|
3 |
|
… |
S |
D |
… |
2 |
A’1 |
A’2 |
|
|
|
standard |
option |
|||||
2.3 Adressage IP
Une adresse IP est un entier codé sur 32 bits, dont
la représentation usuelle est sous forme de 4 entiers décimaux représentant
chacun des 4 octets, comme 130.79.200.1. Remarque : une adresse IP unicast est
une adresse d'interface (et non de machine). En particulier une machine (ou
routeur) ayant plusieurs interfaces réseau à plusieurs adresses IP. En plus des
adresses unicast, IP comporte des adresses broadcast : toutes les
machines dans un (sous-)réseau et multicast (toutes les machines ayant
adhéré à un groupe, voir classe D ci-dessous).
Le système d'adressage initial est basé sur une hiérarchie à deux niveaux : un
numéro de réseau, suivi d'un numéro de machine. Les réseaux sont répartis en 3
classes suivant le nombre d'adresses dispobibles.
|
classe |
préfixe
binaire |
bits
de code de réseau |
bits
de code de machine |
exemple |
|
A |
0 |
8 |
24 |
10.0.0.0 |
|
B |
10 |
16 |
16 |
130.79.0.0 |
|
C |
110 |
24 |
8 |
192.1.2.0 |
|
D (multicast) |
1110 |
|
|
224.0.0.1 |
|
E
(non affecté) |
1111 |
|
|
|
Un réseau, en particulier de classe A ou B, est en
général trop grand pour être géré comme une seule entité, d'où la notion de
sous-réseau : un réseau (de classe A, B ou C) peut être découpé en
sous-réseaux, donnant lieu à une hiérarchie d'adresses à trois niveaux:
Réseau, Sous-Réseau, Machine. Le codage ne permet pas de déterminer comment se
répartissent les bits de Sous-Réseau et de machine. Pour cela un masque de bit,
le masque de (sous-)réseau est nécessaire. Dans ce masque de 32 bits,
les bits à 1 correspondent au réseau et au sous-réseau.
Exemple : 130.79.200.1 et masque 255.255.255.0 indiquent un réseau de
classe B (130.79), un sous-réseau codé sur 8 bits (200) et un numéro de machine
codé sur 8 bits (1). De façon générale, le découpage d'un réseau en
sous-réseaux est invisible de l'extérieur de ce réseau, car les masques
ne sont pas connus. Initialement le découpage d'un réseau en sous-réseau était
fixe : le même masque était utilisé dans tout le réseau. Pour mieux exploiter
l'espace d'adressage disponible, on utilise maintenant un découpage en
sous-réseaux de taille variable. Ceci est rendu possible par les protocoles de
routage qui véhiculent des masques en plus des adresses de réseau, comme le
font OSPF ou RIPv2.
Des mécanismes analogues (super-réseau) permettent de regrouper des
réseaux de numéro contigus, rendant obsolète la notion de classe ( CIDR,
Classless InterDomain Routing : voir par exemple les RFC 1518 et 1519), et
permettant de diminuer la taille des tables de routage par agrégation.
2.4 Fragmentation IP
Comme nous l'avons vu précédemment, la taille d'un
datagramme maximale est de 65535 octets. Toutefois cette valeur n'est jamais
atteinte car les réseaux n'ont pas une capacité suffisante pour envoyer de si
gros paquets. De plus, les réseaux sur Internet utilisent différentes
technologies, si bien que la taille maximale d'un datagramme varie suivant le
type de réseau.
La taille maximale d'une trame est appelée MTU (Maximum Transfer Unit),
elle entraînera la fragmentation du datagramme si celui-ci a une taille plus
importante que le MTU du réseau.
|
Type
de réseaux |
MTU
(en octet) |
|
Arpanet |
1000 |
|
Ethernet |
1500 |
|
FDDI |
4470 |
Le routeur va ensuite envoyer ces fragments de manière indépendante et ré-encapsulé (il ajoute un en-tête à chaque fragment) de telle façon à tenir compte de la nouvelle taille du fragment, et en ajoutant des informations afin que la machine de destination puisse réassembler les fragments dans le bon ordre (rien ne dit que les fragments vont arriver dans le bon ordre étant donné qu'ils sont acheminés indépendamment les uns des autres...).
Pour tenir compte de la fragmentation, chaque
datagramme possède plusieurs champs permettant leur réassemblage:
v
champ déplacement de fragment:
champ permettant de connaître la position du début du fragment dans le
datagramme initial
v
champ identification:
numéro attribué à chaque fragment afin de permettre leur ré-assemblage dans le
bon ordre
v
champ longueur total:
il est recalculé pour chaque fragments
v
champ drapeau:
il est composé de trois bits :
Ø
Le premier n'est pas utilisé
Ø
Le second (appelé DF: Don't Fragment)
indique si le datagramme peut être fragmenté ou non. Si jamais un datagramme a
ce bit positionné à un et que le routeur ne peut pas l'acheminer sans le
fragmenter, alors le datagramme est rejeté avec un message d'erreur
Ø
Le dernier (appelé MF: More Fragments,
en français Fragments à suivre) indique si le datagramme est un fragment
de donnée (1). Si l'indicateur est à zéro, cela indique que le fragment est le
dernier (donc que le routeur devrait être en possession de tous les fragments
précédents) ou bien que le datagramme n'a pas fait l'objet d'une fragmentation
Exemple :

Comme on peut le voir dans la figure, la fragmentation se situe au niveau d'un routeur qui reçoit des datagrammes issus d'un réseau à grand MTU et qui doit les réexpédier vers un réseau à plus petit MTU. Dans cet exemple, si la station A, reliée à un réseau Ethernet, envoie un datagramme de 1300 octets à destination de la station B, reliée également à un réseau Ethernet, le routeur R1 va devoir fragmenter ce datagramme de la manière suivante :
Initialement
Id=X ; L=1320 octet (1300 de données +
20 d’entête IP) ; MF=0 ; DF=0
Fragment 1 :
ID=X ; L=620 (600 de données + 20 d’entête IP) ;
MF=1 ; DF=0 ; offset=0
Fragment 2 :
ID=X ; L=620 (600 de données + 20 d’entête IP) ;
MF=1 ; DF=0 ; offset=600
Fragment 3 :
ID=X ; L=120 (100 de données + 20 d’entête IP) ;
MF=0 ; DF=0 ; offset=1200
Remarque : La taille d'un
fragment est choisie la plus grande possible tout en étant un multiple de 8
octets.
3) Les protocoles
annexes : ARP, ICMP
Lorsque IP est utilisé au dessus d'une couche
liaison ayant son propre système d'adressage, il est nécessaire d'avoir un
mécanisme de mise en correspondance d'adresses. Pour les LAN à diffusion
comme ethernet, le protocole ARP (RFC 826) permet de construire
automatiquement la table (dite table arp) de correspondance : une
requête ARP est envoyée en diffusion ethernet, et contenant l'adresse IP à
résoudre. La station possédant cette adresse IP envoie une réponse ARP au
demandeur.
Le protocole ICMP (Internet Control Message Protocol, RFC 792) permet de
surveiller le bon fonctionnement du protocole IP. Il est basé sur des messages
ICMP transportés par un paquet IP. ICMP est donc considéré comme un protocole
de niveau supérieur. Il utilise dans l'entête IP le numéro de protocole 1. On
distingue deux grands types de messages ICMP:
- des messages d'erreur envoyés par un routeur ou une machine qui ne peut
acheminer un paquet, par exemple
- destination inaccessible
- durée de vie expirée
la commande traceroute est un bon exemple d'utilisation de ces divers
messages d'erreurs.
- des messages de type question/réponse, dont l'exemple le plus connu est le
couple Echo / Echo Reply utilisé par la commande ping.
Divers mécanismes sont prévus pour limiter le trafic de messages ICMP.
4) Envoi d’un paquet
Considérons
une machine reliée à Internet via un réseau local de type ethernet par exemple.
La machine doit disposer (via configuration) des informations suivantes :
- adresse IP de
l'interface réseau (S) et masque de sous-réseau associé (M)
- adresse IP du
routeur par défaut (default gateway G)
- une table ARP
(voir exemple
)
- l'adresse
ethernet s de l'interface S est connue de la carte ethernet.
Algorithme simplifié de l'envoi d'un paquet à
l'adresse IP D
si D appartient au réseau local ( D ET M
= S ET M)
alors
si D ne figure pas dans la table ARP
alors envoyer une requête ARP à l'adresse de
broadcast
si
réponse alors mettre l'adresse ethernet d de D dans la table ARP finsi
finsi
si D figure dans la table avec adresse ethernet d
alors envoyer le paquet IP dans une trame ethernet de
destination d et source s
sinon échec de l'envoi
finsi
sinon
envoyer le paquet au routeur par défaut dans une trame ethernet de destination
g et de source s, où g est l'adresse ethernet de G, obtenue par ARP.
finsi
5) Le routage
Un routeur doit participer au bon acheminement des
paquets vers leur destination. On distingue deux opérations : la commutation
des paquets et le routage proprement dit. Chaque routeur dispose d'une table
de routage comportant pour chaque entrée:
destination, prochain saut, interface de sortie, (métrique)
La commutation des paquets consiste, pour chaque paquet
entrant d'adresse destination D, à chercher dans la table la destination correspondant
le mieux à D. En général, les destinations dans la table sont des
(sous)-réseaux, voire même une adresse par défaut (0.0.0.0). La commutation est
une opération simple mais qui doit être effectuée très rapidement.
Le routage est le processus qui permet de construire la table de
routage. Pour IP, ce processus est en général dynamique et distribué, au moyen
de protocoles de routage.
On distingue le routage intra-domaine et inter-domaine. Dans le premier cas,
les informations de routage circulent entre routeurs d'un même domaine, par
exemple le réseau interne d'une entreprise ou le réseau d'un opérateur. Le
routage se fait principalement sur des critères techniques (route "la plus
courte").
Des informations de routage doivent aussi circuler entre des domaines
différents (principe même d'Internet). Ici les critères économiques dominent,
et les informations de routage sont filtrées en fonction de la politique de
routage de chaque domaine (protocole BGP par exemple).
6) Le protocole de
routage : OSPF
Open Shortest Path First : RFC
2328, avril 1998, standard 54.
6.1 Principe
OSPF est un protocole de routage IP de type état
des liens (link state). Il est normalisé par l’IETF pour être utilisé
comme protocole de routage à l’intérieur d’un domaine (intra domaine).
Le principe de base est simple, bien que le
protocole soit assez complexe ;
Principe du routage par état des liens :
chaque routeur a la charge de déterminer l’état des connexions réseaux
adjacentes (lien). Cette information est ensuite diffusée à tous les routeurs,
qui disposent donc du graphe complet du réseau. A chaque changement de ce
graphe, un routeur calcule l’arbre des plus courts chemins depuis lui-même vers
toutes les destinations. Le premier saut dans l’arbre vers chacune des destinations
fournit ensuite la table de routage proprement dite.
Les protocoles à état des liens sont généralement
préférés aux protocoles par vecteur de distance (comme RIP), grâce à :
·
·
une plus grande rapidité de convergence
·
·
une moins grande quantité d’information de routage à
transmettre (les mises à jour sont incrémentales)
·
·
une meilleure protection contre les boucles de routage (les
boucles peuvent apparaître pendant des situations transitoires où tous les
routeurs n’ont pas la même vue du réseau).
A partir du principe
simple du routage par état des liens, un protocole réel doit prendre en compte
plusieurs problèmes :
- il
faut contrôler les routeurs qui peuvent dialoguer (ceci donne lieu au sous
protocole HELLO qui permet de découvrir les routeurs voisins et de
vérifier qu’ils sont toujours accessibles)
- le
réseau n’est pas constitué uniquement de liaisons point à point, il faut
donc modéliser les autres types de liaisons, les liens à diffusion comme
ethernet par exemple
- il
faut diffuser de façon fiable l’information sur l’état des liens
(protocole de flooding)
- afin
de pouvoir gérer des réseaux (domaine de routage) assez grands, il faut
pouvoir les découper en zones (aires ou area) et définir quel type d’information (nécessairement
condensée) passe d’une aire à une autre (notion de routeurs frontière
d’aire et de routage inter aire)
- il
faut aussi pouvoir échanger des informations de routage avec l’extérieur
(notion de routeur de frontière de système autonome).
6.2 Modèle de réseau
Un réseau est
modélisé par un graphe. Le modèle simple où les sommets sont les routeurs et
les arêtes sont les liens entre routeurs n’est pas suffisant, à cause en
particulier des liens multipoints comme ethernet. Le modèle est donc un graphe
où les sommets sont soit des routeurs, soit des réseaux multipoint, et les
arêtes représentent des adjacences entre deux sommets. Les arêtes sont
orientées, ce qui permet de traiter des graphes où les coûts sont asymétriques.
En revanche les arêtes sont bi directionnelles.
Un lien correspond à une
arête, et l’état d’un lien (EL) est annoncé par le sommet source de l’arête. En
pratique, si la source de l’arête est un réseau (un lien multipoint ethernet
par exemple), l’annonce ne peut pas être faite par ce réseau. C’est un routeur
(dit routeur désigné) qui s’en chargera.
Le protocole peut être
divisé en plusieurs parties :
- découverte
des voisins et établissement des relations d’adjacence
- diffusion
des états des liens et mise à jour de la base de données des liens
- calcul
de la table de routage pour les destinations dans la même aire
- calcul
de la table de routage pour les destinations hors de l’aire (inter-aire)
- calcul de la table de routage pour les
destinations hors du domaine.
6.3 Découverte des voisins et adjacence
·
chaque routeur diffuse cycliquement sur chaque interface
un message Hello, envoyé à une adresse multicast (ALL _OSPF_ROUTERS). Ce
message contient aussi l’identité des autres routeurs connus (grâce à leurs
messages Hello) sur cette même interface. Ceci permet de savoir si le voisinage
entre deux routeurs est bi-directionnel (R1 voit que R2 le voit). Cet échange
permet aussi d’élire le routeur désigné (DR = Designated Router) et le
routeur désigné de secours (BDR = Backup DR) pour un lien multipoint. L’élection est basée sur la priorité
(configurable) des routeurs ou à défaut sur l’identificateur (adresse IP) des
routeurs.
·
deux routeurs R1 et R2 établissent une relation
d’adjacence
o
Si R1-R2 est un lien point à point ou bien
o
Si R1 ou R2 est le
DR ou le BDR sur un lien multipoint
· Lorsqu’une nouvelle adjacence est établie entre deux routeurs, ils synchronisent leurs bases de données d’états des liens
6.4 Diffusion des états et des liens
- un état des liens (EL) est créé par un routeur, par exemple le
lien point à point reliant R1 à R2
est créé par R1.
- Lors
d’un changement d’EL, ou lors de la création d’une nouvelle adjacence, et
ensuite cycliquement (par exemple toutes les 30 minutes), une annonce
d’états des liens (AEL) est diffusée de proche en proche à tous les
routeurs. Pour permettre cette diffusion, une AEL comporte les attributs
suivants :
- Le
routeur annonçant l’AEL
- Un
identifiant (adresse IP)
- Un
numéro de séquence qui permet de savoir si une AEL est plus récente
qu’une autre de même identifiant
- Un
âge (les AEL ont une durée limitée, par défaut 1 heure, et doivent être
rafraîchis cycliquement)
- Un
type (routeur, réseau, récapitulation de réseau, récapitulation de réseau
externe, externe)
- Un
total de contrôle (checksum)
-
Chaque AEL comporte une liste d’EL, avec son
identifiant (adresse et masque) et sa métrique. Par exemple, un routeur
construit une AEL de type routeur, qui
liste tous ses liens de type routeur (toutes les arêtes sortantes du routeur
dans le graphe). De même un DR construit une AEL de type réseau contenant tous
les routeurs connectés à ce réseau (toutes les arêtes sortantes de ce réseau
multipoint qui ont par convention une métrique nulle).
- la
diffusion se fait par inondation : quand un routeur apprend une
nouvelle AEL (ou version d’AEL), il la propose à tous les routeurs
adjacents sauf celui qui le lui a fourni.
Remarque : si un lien
sortant d’un routeur n’est plus opérationnel, ce routeur crée une nouvelle
version d’AEL de type routeur, ne contenant plus ce lien, puis le diffuse. La
disparition d’un lien est donc apprise de façon implicite.
6.5 Calcul de la table de routage
La base d’EL forme un graphe
·
un EL de type routeur a pour origine un routeur et
désigne un réseau ou un routeur accessible depuis ce routeur
·
un EL de type réseau a pour origine un réseau
multipoint et désigne un routeur accessible depuis ce réseau (cet EL est
annoncé par le DR du réseau)
·
la métrique par défaut d’OSPF est une métrique
additive égale à 108 /d , où
d est le débit binaire
·
sur ce graphe, un routeur exécute l’algorithme de
Dijkstra :
Principe de l’Algorithme
de Dijkstra
Construit un arbre A des
plus courts chemins depuis la racine R vers tous les sommets
Données : liste des
sommets N et des arêtes E avec leur coût : l’arête (x,y) a un coût
noté coût(x,y)
Initialement R Î N est racine, la
liste C des candidats sommets à ajouter à l’arbre est vide. L’arbre A est
initialisé à R
Répéter
Pour chaque lien (x, y) de E, x ÎA, y ÏA, calculer la distance (R,y) = distance(R,x)+coût(x,y)
-
si y est déjà dans C avec un coût supérieur,
remplacer le coût
-
si y n’est pas dans C, l’ajouter
Si la liste C n’est pas vide, choisir v dans C de distance la plus faible, ajouter v et l’arête qui permet d’obtenir cette distance minimale à A et enlever v de C
Tant que C n’est pas vide
-
Les destinations
correspondent aux identificateurs des liens. Le prochain saut N vers une
destination D est donné par la première
arête (R, N) de l’unique chemin de l’arbre de R à D.
6.6 Routage inter-zone
Afin de pouvoir
gérer de grands réseaux OSPF, ceux-ci peuvent être découpés en une hiérarchie
de zones (ou aires) :
·
une zone backbone (zone 0)
·
interconnectant une ou plusieurs zones.
·
les AEL de type routeur et réseau ne sont pas
diffusés à l’extérieur de leur zone, ils sont remplacés par des AEL résumés.
Une zone doit être connexe.
Deux zones sont reliées par un ou plusieurs routeurs communs (BR : Border
Router). La frontière entre zones
passe donc à travers les routeurs et non pas entre les routeurs.
Un routeur frontière
calcule d’abord sa table de routage intra-zone pour chaque zone à laquelle il
appartient comme en 5), puis il intègre les états de liens récapitulatifs pour
calculer sa table inter-zone. Il génère des EL récapitulatifs par zone qu’il envoie dans les autres zones : un
routeur frontière R ayant une destination D dans sa table, avec une
métrique d et un prochain saut N envoie un EL récapitulatif pour la destination
D à ses voisins n’appartenant pas à la même zone que N, et indiquant une
métrique d. Tout se passe donc comme si R était connecté à D par un lien de
métrique d.
On peut noter qu’à
l’extérieur d’une zone, on perd l’information sur la topologie interne de la
zone.
6.6 Routage externe
De façon similaire au
routage inter-zone, un routeur frontière construit des EL externes qu’il
diffuse dans le domaine OSPF. Les routeurs OSPF construisent leur table
inter-domaine après avoir construit leur table inter-zone. En particulier, une
route entre deux points d’une zone ne peut sortir du domaine ni même de la
zone.
Exemple
On considère un réseau composé de 2 routeurs et 3 réseaux :

Vue
logique du graphe, avec le coût de chaque arête (1 = 100 Mb/s)

Initialement le réseau 192.168.11.0 est désactivé. Toutes les
informations ci-dessous sont lues sur le routeur2 (messages sur les routeurs
cisco) (des informations logiques correspondant au graphe ci-dessus ont été
ajoutées en bleu, et certaines modifications
importantes en rouge).
Interfaces de routeur2 (R2)
Loopback0 is up, line protocol is up
Internet
Address 192.168.12.1/32, Area 0
Process ID
100, Router ID 192.168.12.1, Network Type LOOPBACK, Cost: 1
Loopback
interface is treated as a stub Host
FastEthernet0/1 is up, line protocol is up
Internet
Address 192.168.10.254/24, Area 0
Process ID
100, Router ID 192.168.12.1, Network Type BROADCAST, Cost: 1
Transmit
Delay is 1 sec, State BDR, Priority 1
Designated
Router (ID) 192.168.11.1 (R1), Interface
address 192.168.10.1
Backup
Designated router (ID) 192.168.12.1 (R2),
Interface address 192.168.10.254
Timer
intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
Hello due
in 00:00:01
Index 1/1,
flood queue length 0
Next
0x0(0)/0x0(0)
Last flood
scan length is 1, maximum is 1
Last flood
scan time is 0 msec, maximum is 4 msec
Neighbor Count
is 1, Adjacent neighbor count is 1
Adjacent
with neighbor 192.168.11.1 (Designated
Router)
Suppress
hello for 0 neighbor(s)
Les
voisins OSPF de routeur 2. On observe qu’il y en a un seul, routeur1
(192.168.11.1) qui est le routeur désigné (DR) du réseau 192.168.10.0, routeur2
étant le BDR d’après l’état des interfaces ci-dessus.
Neighbor ID
Pri State Dead Time Address Interface
192.168.11.1 (R1) 1
FULL/DR 00:00:33 192.168.10.1 FastEthernet0/1
Un résumé
de la base de données donne 2 annonces
de type routeur (une pour chaque routeur) et une annonce de type net pour le
réseau multipoint 192.168.10.0
OSPF Router with ID (192.168.12.1) (Process ID 100)
Router Link States (Area 0)
Link ID
ADV Router Age Seq# Checksum Link count
192.168.11.1
192.168.11.1(R1)259 0x8000010B 0xEF64 1
192.168.12.1
192.168.12.1(R2)761 0x80000100 0x2DAA 2
Net Link States (Area 0)
Link ID
ADV Router Age Seq# Checksum
192.168.10.1 192.168.11.1(R1)1251 0x800000FE 0xEC79
Plus
précisément, l’annonce de type net donne
deux routeurs adjacents au réseau 192.168.10.0 :
Net Link States (Area 0)
Routing Bit
Set on this LSA
LS age: 1301
Options: (No
TOS-capability, DC)
LS Type:
Network Links
Link State
ID: 192.168.10.1 (address of Designated Router)
Advertising
Router: 192.168.11.1
LS Seq
Number: 800000FE
Checksum:
0xEC79
Length: 32
Network Mask:
/24
Attached Router: 192.168.11.1 (N2-R1)
Attached Router: 192.168.12.1 (N2-R2)
De même
les 2 annonces d’états des liens de type routeur contiennent :
Router Link States (Area 0)
LS age: 346
Options: (No
TOS-capability, DC)
LS Type:
Router Links
Link State
ID: 192.168.11.1
Advertising
Router: 192.168.11.1
LS Seq
Number: 8000010B
Checksum:
0xEF64
Length: 36
Number of
Links: 1
Link
connected to: a Transit Network
(Link ID)
Designated Router address: 192.168.10.1
(Link
Data) Router Interface address: 192.168.10.1
Number of
TOS metrics: 0
TOS 0 Metrics: 1 (R1-N2)
LS age: 848
Options: (No
TOS-capability, DC)
LS Type:
Router Links
Link State
ID: 192.168.12.1
Advertising
Router: 192.168.12.1
LS Seq
Number: 80000100
Checksum:
0x2DAA
Length: 48
Number of
Links: 2
Link
connected to: a Stub Network
(Link ID)
Network/subnet number: 192.168.12.1
(Link
Data) Network Mask: 255.255.255.255
Number of
TOS metrics: 0
TOS 0 Metrics: 1 (R2-N3)
Link connected to: a Transit Network
(Link ID)
Designated Router address: 192.168.10.1
(Link
Data) Router Interface address: 192.168.10.254
Number of
TOS metrics: 0
TOS 0 Metrics: 1 (R2-N2)
On
retrouve bien que routeur2 a deux connexions (avec 192.168.10.O et
192.168.12.0) alors que routeur 1 a seulement une connexion avec 192.168.10.0
La table
de routage du routeur
router2#sho ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M
- mobile, B - BGP
D -
EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
NSSA external type 2
E1 - OSPF
external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS
level-2, ia - IS-IS inter area
* -
candidate default, U - per-user static route, o - ODR
P -
periodic downloaded static route
Gateway of last resort is not set
192.168.12.0/32 is subnetted, 1 subnets
C
192.168.12.1 is directly connected, Loopback0
C
192.168.10.0/24 is directly connected, FastEthernet0/1
Après
activation du réseau 192.168.11.0 sur le routeur 1, on observe que le
l’annonce de type routeur de routeur1 a changé (le numéro de séquence a
augmenté de 1) et contient maintenant un
lien de plus :
OSPF Router with ID (192.168.12.1) (Process ID 100)
Router Link States (Area 0)
Link ID
ADV Router Age Seq# Checksum Link count
192.168.11.1
192.168.11.1 70 0x8000010C
0x527A 2
192.168.12.1
192.168.12.1 988 0x80000100 0x2DAA 2
Net Link States (Area 0)
Link ID
ADV Router Age Seq# Checksum
192.168.10.1 192.168.11.1 1478 0x800000FE
0xEC79
Le nouveau
lien correspond bien à la connexion de
routeur 1 au réseau 192.168.11.0 :
OSPF Router with ID (192.168.12.1) (Process ID 100)
Router Link States (Area 0)
LS age: 89
Options: (No
TOS-capability, DC)
LS Type:
Router Links
Link State
ID: 192.168.11.1
Advertising
Router: 192.168.11.1
LS Seq
Number: 8000010C
Checksum:
0x527A
Length: 48
Number of
Links: 2
Link connected to: a Stub Network
(Link ID) Network/subnet number: 192.168.11.1
(Link Data) Network Mask: 255.255.255.255
Number of TOS metrics: 0
TOS 0 Metrics: 1
(nouveau lien R1-N1)
Link connected to: a Transit Network
(Link ID)
Designated Router address: 192.168.10.1
(Link
Data) Router Interface address: 192.168.10.1
Number of
TOS metrics: 0
TOS 0
Metrics: 1
LS age: 1010
Options: (No
TOS-capability, DC)
LS Type:
Router Links
Link State
ID: 192.168.12.1
Advertising
Router: 192.168.12.1
LS Seq
Number: 80000100
Checksum:
0x2DAA
Length: 48
Number of
Links: 2
Link
connected to: a Stub Network
(Link ID)
Network/subnet number: 192.168.12.1
(Link
Data) Network Mask: 255.255.255.255
Number of
TOS metrics: 0
TOS 0
Metrics: 1
Link
connected to: a Transit Network
(Link ID)
Designated Router address: 192.168.10.1
(Link
Data) Router Interface address: 192.168.10.254
Number of
TOS metrics: 0
TOS
0 Metrics: 1
La table
de routage IP contient bien le réseau 192.168.11.0, accessible via le routeur1, et appris par OSPF, avec une
métrique de 2 (traversée des réseaux N2 puis N1) :
router2#
router2#sho ip rou
Codes: C - connected, S - static, I - IGRP, R - RIP, M
- mobile, B - BGP
D -
EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF
NSSA external type 2
E1 - OSPF
external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS
level-2, ia - IS-IS inter area
* -
candidate default, U - per-user static route, o - ODR
P -
periodic downloaded static route
Gateway of last resort is not set
192.168.12.0/32 is subnetted, 1 subnets
C
192.168.12.1 is directly connected, Loopback0
C
192.168.10.0/24 is directly connected, FastEthernet0/1
192.168.11.0/32 is subnetted, 1 subnets
O
192.168.11.1 [110/2] via 192.168.10.1, 00:01:50, FastEthernet0/1
On peut
faire l’opération inverse (désactiver le réseau 192.168.11.0) sur routeur 1, et
observer que les annonces d’état des liens de type routeur sont revenues à
l’état initial, et que le numéro de séquence a de nouveau été augmenté :
OSPF Router with ID (192.168.11.1) (Process ID 100)
Router Link States (Area 0)
LS age: 68
Options: (No
TOS-capability, DC)
LS Type:
Router Links
Link State
ID: 192.168.11.1
Advertising
Router: 192.168.11.1
LS Seq
Number: 8000010D
Checksum:
0xEB66
Length: 36
Number of
Links: 1
Link
connected to: a Transit Network
(Link ID)
Designated Router address: 192.168.10.1
(Link
Data) Router Interface address: 192.168.10.1
Number of
TOS metrics: 0
TOS 0
Metrics: 1
LS age: 1158
Options: (No
TOS-capability, DC)
LS Type:
Router Links
Link State
ID: 192.168.12.1
Advertising
Router: 192.168.12.1
LS Seq
Number: 80000100
Checksum:
0x2DAA
Length: 48
Number of
Links: 2
Link
connected to: a Stub Network
(Link ID)
Network/subnet number: 192.168.12.1
(Link
Data) Network Mask: 255.255.255.255
Number of
TOS metrics: 0
TOS 0
Metrics: 1
Link
connected to: a Transit Network
(Link ID)
Designated Router address: 192.168.10.1
(Link
Data) Router Interface address: 192.168.10.254
Number of
TOS metrics: 0
TOS 0
Metrics: 1